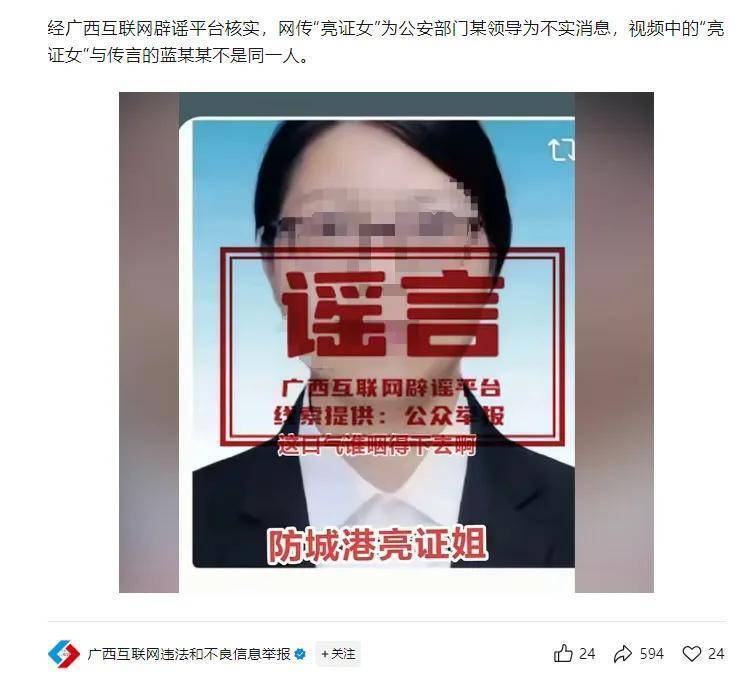
本文为捷径规则分享

不知道捷径App怎么使用,可以点下面黄字看我微博发过的另一篇文章
iOS12上的「捷径」怎么用?从零开始教你快速上手
https://www.icloud.com/shortcuts/9447197a714a42e0b1b4b5fd6beac89d
https://www.icloud.com/shortcuts/e9f637bffeca4650822da46c1617072e
https://www.icloud.com/shortcuts/5764e6f518434dfda93e1cf96fe3c702
https://www.icloud.com/shortcuts/4dbc331549564f3d8edaa8e1d581f84e
https://www.icloud.com/shortcuts/c81ac91707684b909d592505e6b4121e
https://www.icloud.com/shortcuts/995cd396580c4eab8e5caa09e7b387b6
https://www.icloud.com/shortcuts/95ea74e814aa4efc9d8cef2a4a342163
https://www.icloud.com/shortcuts/bfc436f0fe6d478fb9f6934d0217db4f
https://www.icloud.com/shortcuts/2fcbce53a5bc47dc8dd0cb1910e2c2c1
https://www.icloud.com/shortcuts/03171e553f5d41b38d946e2cbdcc9e4e
https://www.icloud.com/shortcuts/89359b7c17214d2592607595d2fad089
https://www.icloud.com/shortcuts/be9cee3a9fc24dcabbc423a6f3c60c62
https://www.icloud.com/shortcuts/ceb6ab44609b4097a4070b51955744fb
https://www.icloud.com/shortcuts/8ca0dcff24234fb5b75a5a057ec92567
https://www.icloud.com/shortcuts/c1a8aa51d82842c6a6dabcd6cd4d91e0
https://www.icloud.com/shortcuts/9eee6c39caab4fdb9e62b32d10573901
https://www.icloud.com/shortcuts/db4dc327f7374c3e9cf06978feae1146
https://www.icloud.com/shortcuts/8dc53317b0ee436186392d433eeb1f98
https://www.icloud.com/shortcuts/12f7a7e8c3e64e08b55007e9b2700bc6
https://www.icloud.com/shortcuts/a277d6dfe0774a1b81bc8e78a2f89558
https://www.icloud.com/shortcuts/d995516af5e04f24a377e20e56ff6a46
https://www.icloud.com/shortcuts/c6e4baf943224a3db02a38b925355c0b
https://www.icloud.com/shortcuts/bb90163d7ce1420993e78d5429a71bfb
https://www.icloud.com/shortcuts/492dc7f3b5f843f2a0804f7f3009f56f
https://www.icloud.com/shortcuts/3c79f99ad4f9410e91d9985463c3328f
https://www.icloud.com/shortcuts/4c0633d4948046ceab0d3bc495b2b911
https://www.icloud.com/shortcuts/89df07bc2cd44aa29796dc913ba98d54
https://www.icloud.com/shortcuts/709f86b54da54da0a1daf0c195ce3e99
https://www.icloud.com/shortcuts/70b019ff6ac7482f8a88bddac50e3031
https://www.icloud.com/shortcuts/a5dc321e9420452eb7ba06eed9a46fb6
https://www.icloud.com/shortcuts/95c735eed5b34358a588680c3ddf4ec8
https://www.icloud.com/shortcuts/3b799306266d43cd83ca7a32bfc63041
https://www.icloud.com/shortcuts/bbd1e2af3c4d49879067ecabc071c2a9
https://www.icloud.com/shortcuts/3e6c50fc89844b46bb8dde40fb1f834e
https://www.icloud.com/shortcuts/64976d4234804d03a124b7d0e9c75bae
https://www.icloud.com/shortcuts/2da7d052a8d64464bd16b25f1ebd0e70